Software • 20. Januar 2021
Mehrere PostgreSQL-Instanzen auf einer PostgreSQL-Installation
Für meine Arbeit an Kundenprojekten habe ich nicht nur verschiedene Datenbank-Verbindungen zu PG-Datenbanken in meinem pgAdmin konfiguriert, ich habe auch auf meinem Arbeitsrechner mehrere Datenbanken eingerichtet, die Kundendaten enthalten. Natürlich enthalten diese Datenbank-Namen in der Regel den Namen des Kunden oder des Projektes. In Präsentationen bei Kunden sollen die Namen der anderen Projekte nicht unbedingt angezeigt werden, schon gar nicht sollten sie bei Schulungen und Präsentationen mit zahlreichen mir teilweise unbekannten Teilnehmern für alle sichtbar sein.
Über die Frage wie ich Datenbankverbindungen in pgAdmin verstecken kann, bin ich auf die Möglichkeit gestoßen, mehrere Instanzen innerhalb meiner Installation zu konfigurieren, die getrennt voneinander laufen und auf jeweils eigenen Ports lauschen.
Das geht ganz einfach, wenn erst einmal der richtige Einstieg gefunden ist und bedurfte unter Ubuntu keiner Installation weiterer Tools oder Software. Die PostgreSQL-Installation über die Paketverwaltung bringt die Mittel dafür schon mit.
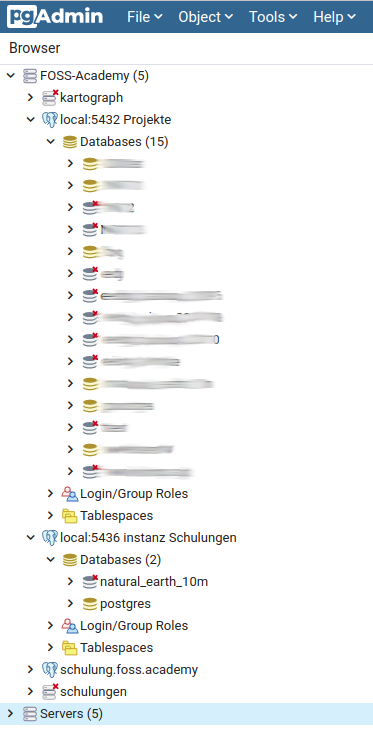
Im Ergebnis habe ich nun nicht nur in pgAdmin einen weiteren Datenbankserver (im Screenshot der local:5436 instanz Schulungen), die Instanzen sind auch auf der Festplatte komplett voneinander getrennt und können unabhängig voneinander konfiguriert werden. Den Baum local:5432 Projekte kann ich nun bei Schulungen und Workshops einfach zugeklappt lassen.
Mit dem Kommandozeilenprogramm pg_lsclusters können wir uns die vorhanden Instanzen auf unserem Rechner anzeigen lassen:
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
10 main 5433 online postgres /var/lib/postgresql/10/main /var/log/...
12 main 5432 online postgres /var/lib/postgresql/12/main /var/log/...
12 schulungen 5434 online postgres /var/lib/postgresql/12/schulungen /var/log/...Bei mir läuft ein PG 10 und ein PG 12 jeweils mit dem Cluster main – das sind natürlich zwei unterschiedliche Installationen von PostgreSQL 10 und PostgreSQL 12. Den dritten Cluster schulungen habe ich innerhalb der Installation der 12er Version manuell angelegt. Der Befehl dafür lautet pg_createcluster und muss mit root-Rechten ausgeführt werden:
$ pg_createcluster 12 schulungen
Creating new PostgreSQL cluster 12/schulungen ...
/usr/lib/postgresql/11/bin/initdb -D /var/lib/postgresql/12/schulungen --auth-local peer --auth-host md5
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "en_US.UTF-8".
The default database encoding has accordingly been set to "UTF8".
The default text search configuration will be set to "english".
Data page checksums are disabled.
fixing permissions on existing directory /var/lib/postgresql/11/schulungen ... ok
creating subdirectories ... ok
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
selecting dynamic shared memory implementation ... posix
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... ok
Success. You can now start the database server using:
pg_ctlcluster 12 schulungen startWie in der letzten Zeile der Ausgabe angegeben, kann die neue Instanz nun wie folgt gestartet werden:
pg_ctlcluster 12 schulungen startWie können wir diesen neuen Cluster nutzen?
Wie oben bereits zu sehen, hat jeder Cluster einen eigenen Port, über den auf den Cluster zugegriffen werden kann. In unserem Fall ist das 5434. pg_createcluster. Dieser nimmt per default den nächsthöheren freien PostgrSQL-Port (5432 ist durch den Cluster main von PG 12 bereits belegt gewesen und PG 10 nutzt bei mir den Port 5433). Der Port kann beim Erstellen des Clusters auch spezifiziert werden (s.u.).
Unter Angabe des Ports 5434 können wir uns nun also mit dem neuen Cluster verbinden:
$ sudo -su postgres
postgres@nebukadnezar:$ psql -p5434
...
postgres=# Damit auch die Verbindung über pgAdmin funktioniert muss jetzt noch ein Passwort für den Postgres-User eingegeben werden (oder ein neuer User mit Passwort angelegt werden, aber hier handelt es sich nur mein Notebook und Datenbanken für Schulungen, daher arbeite ich mit dem Standard-User postgres):
postgres=# \password
Neues Passwort eingeben:
Geben Sie es noch einmal ein:
postgres=#Danach können wir uns via localhost in pgAdmin mit dem Cluster verbinden.
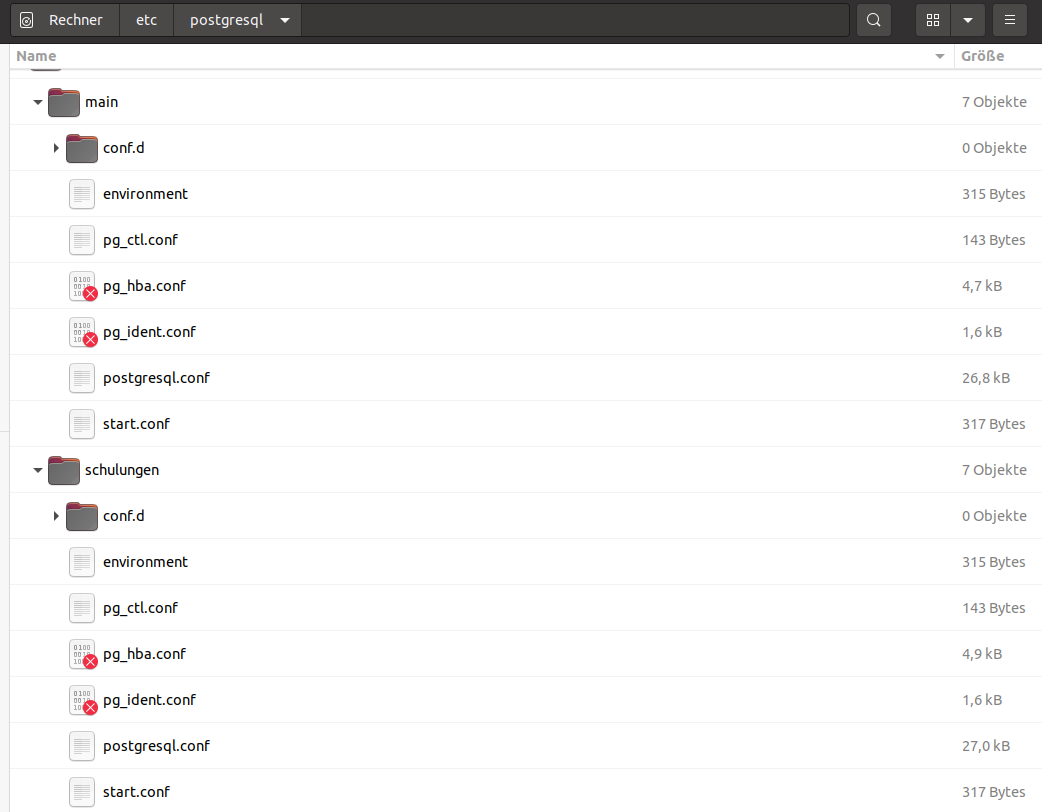
Der neue Cluster läuft unabhängig von den vorhandenen Standard-Clustern (main) und verfügt über einen eigenen Verzeichnisbaum für die Konfigurations- und Log-Dateien. Auf dem lokalen Notebook kann ich darauf verzichten auch getrennte tablespaces anzulegen:
Optionen:
pg_createlcuster erlaubt diverse Aufrufparameter. So kann man zum Beispiel einen Port angeben, wenn nicht automatisch hoch gezählt werden soll:
$ pg_createcluster 12 schulung -p 5551Eine vollständige Liste der Optionen erhält man, wenn wann pg_createcluster ohne weitere Parameter aufruft:
$ pg_createcluster 12 schulungen
Creating new PostgreSQL cluster 12/schulungen ...
/usr/lib/postgresql/11/bin/initdb -D /var/lib/postgresql/12/schulungen --auth-local peer --auth-host md5
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "en_US.UTF-8".
The default database encoding has accordingly been set to "UTF8".
The default text search configuration will be set to "english".
Data page checksums are disabled.
fixing permissions on existing directory /var/lib/postgresql/11/schulungen ... ok
creating subdirectories ... ok
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
selecting dynamic shared memory implementation ... posix
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... ok
Success. You can now start the database server using:
pg_ctlcluster 12 schulungen startIm gesamten Zusammenhang ist vielleicht auch nicht uninteressant, dass ein Cluster separat gestartet bzw. beendet werden kann. Es muss also bei Änderungen der Konfiguration nicht der gesamte Service neugestartet werden; es ist möglich diesen anzulegen, aber dann nur bei Bedarf zu starten:
pg_ctlcluster - start/stop/restart/reload a PostgreSQL clusteWeiterführende Informationen:
